
You pull your blanket more tightly around you and let yourself sink into the couch cushions. The fire crackles merrily. As you watch the flames, your heartbeat slows. Your breaths lengthen and deepen. Your shoulders loosen.
How do you feel? Happy?
You dangle the rope toy playfully, dodging as your dog jumps for it, before sprinting onto the open field and flinging it as far as you can. Your dog bounds across the grass to drop the now slightly soggier toy at your feet. As you kneel down to pet the wagging ball of fur, you feel your heart pounding. You breath rapidly and your face stretches into a glowing smile.
Isn’t that also happiness?
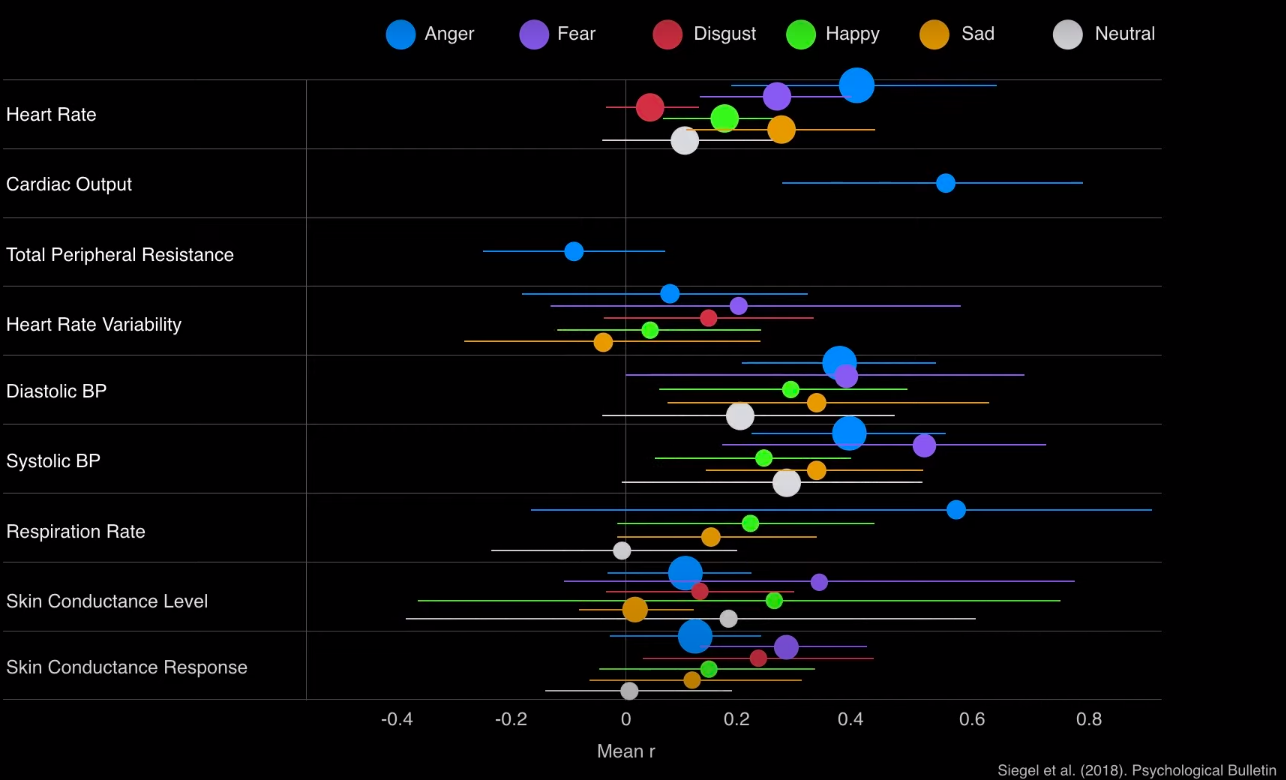
And yet, your heart and your breath changed in opposite directions. In fact, the change in your heart rate and breath when you were playing with your dog better matched being chased by a bear than relaxing on a couch.
Shouldn’t these two experiences of happiness have something in common? And if your heart beats the same when you are running with your dog as it does when you are running from a bear, where do we draw the line between happiness and fear? Do the words we use to describe emotion have any biological meaning?
Researchers in Northeastern’s Psychology/Engineering/Neuroscience (PEN) group investigated this question in a recently published paper. They used machine learning approaches to search for links between instances of emotion and measurable biological responses in three datasets. For each dataset, the PEN team conducted both supervised and unsupervised machine learning analyses.
Supervised analysis refers to approaches where researchers provide a model with a set of categories and try to learn the patterns that distinguish one from the other. In the case of emotion, that meant providing the models with labels like happy, sad, angry and so on. For instance, one of the datasets came from a study that measured brain activity in participants after they had listened to immersive scenarios that evoked intense experiences of happiness, sadness, and fear. In the supervised approach, researchers used those emotion words as labels, and trained the model on a sample of the data to teach it which patterns in brain activity distinguished each emotion category from the others. The model then used brain data to predict whether people were feeling instances of happiness, sadness, or fear for the rest of the dataset.
Unsupervised learning approaches, on the other hand, discover reliable patterns in data without guidance from human labels. The models applied in the paper looked for groups, or clusters, of biological data. Each discovered cluster was associated with combinations of data values or ranges, and these were used to identify the categories that best described any regularities in the data.
Researchers compared the results of supervised and unsupervised learning approaches to evaluate the usefulness of commonsense emotion categories (e.g. happiness) for describing changes in brain activity and physiology, as well as the potential of machine learning applications to discover categories in psychological data. They found that the supervised algorithms generated data patterns that distinguished pre-labeled emotion categories from one another more often than could be explained by chance. The unsupervised algorithms also discovered highly reliable categories in the data, but the two did not match: unsupervised machine learning did not reveal a single category (a single data pattern) for instances of happiness, sadness, fear, or any other emotion category. The researchers suggest two explanations for this difference. Measurement errors or problems with the study design are one possibility. If this is the case, then unsupervised algorithms should reveal stable biological patterns for the commonsense emotion categories used in the studies, like happiness, fear, and sadness, when data are collected under different research conditions. The other possibility is that there are no distinct and measurable biomarkers for each emotion category because any emotion category is a population of highly diverse instances, each one tailored to the particulars of a specific situation. In this case, trying to find a single biomarker, or pattern of data, to characterize all the instances of an emotion category like happiness, across all people and all situations, is misguided because it misunderstands the nature of emotion.
The results of this paper show that we must question whether commonsense labels that exist in a western culture like ours—happiness, memory, decision making—are the best categories for guiding science. This has serious implications for the kinds of studies that are run and the kinds of questions that should be asked. It is a kind of bias to assume that our everyday category labels carve nature at its joints.
Another important point highlighted by the paper is the importance of being aware of bias, in research and when applying machine learning in particular. Computer algorithms are never neutral. They are shaped by the beliefs of the people who create and train them. The impact of this on everything from the COMPAS algorithm used in US court systems to Amazon’s hiring algorithm is well documented.
Correctly implemented, artificial intelligence has the potential to advance science in ways unimaginable twenty or even ten years ago. Improvements in data collection and database management means greater volumes of data, and computers have the potential to process and analyze these volumes with a comprehensiveness that would take years by hand. The opportunities for machine learning in scientific research are expanding, but we must be aware of our starting assumptions and counter bias every step of the way.
